1. Overview¶
EQTransformer is a multi-task deep neural network for simultaneous earthquake detection and phase picking with a hierarchical attentive model. It mainly consists of one very deep encoder and three separate decoders (detector, P-picker, and S-picker branches) with an attention mechanism. Attention mechanisms in Neural Networks are inspired by human visual attention. Humans focus on a certain region of an image with high resolution while perceiving the surrounding image at low resolution and then adjusting the focal point over time. Our model emulates this through two levels of attention mechanism in a hierarchical structure. one at the global level for identifying an earthquake signal in the input time series, and one at the local level for identifying different seismic phases within that earthquake signal. Two levels of self-attention (global and local) help the neural network capture and exploit dependencies between local (individual phases) and global (full-waveform) features within an earthquake signal. This model has several distinctive characteristics: 1) it is the first hierarchical-attentive model specifically designed for earthquake signal; 2) with 56 activation layers, it is the deepest network that has been trained for seismic signal processing; 3) it has a multi-task architecture that simultaneously performs the detection and phase picking - using separate loss functions - while modeling the dependency of these tasks on each other through a hierarchical structure; 4) in addition to the prediction probabilities, it provides output variations based on Bayesian inference; 5) it is the first model trained using a globally distributed training set of 1.3 M local earthquake observations; 6) it consists of both convolutional and recurrent neurons. Read our paper for more details.
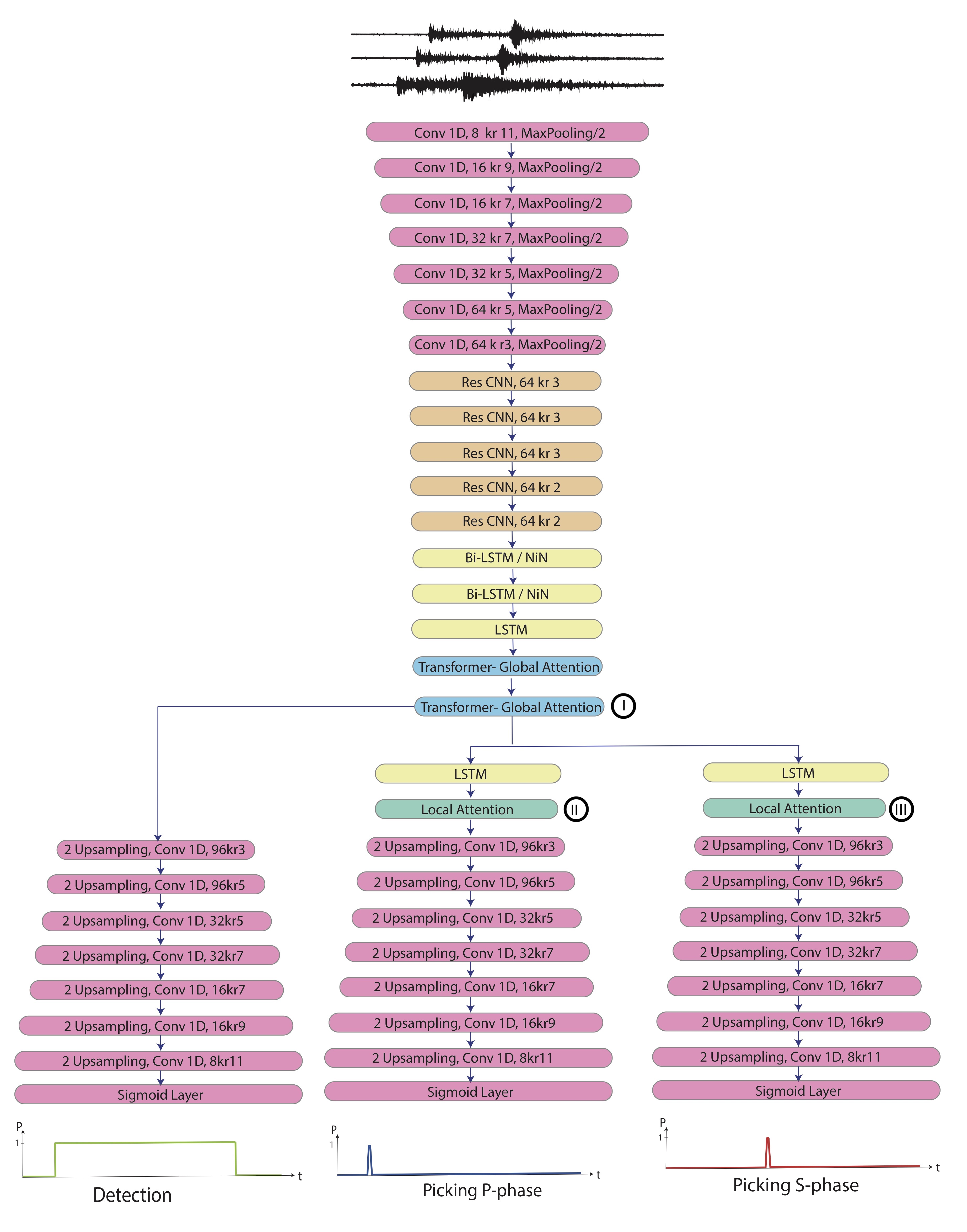
Architecture of EQTransformer
1.1. Dataset¶
STanford EArthquake Dataset (STEAD) is used to train the EQTransformer. STEAD is a large-scale global dataset of labeled earthquake and non-earthquake signals. Here we used 1 M earthquake and 300 K noise waveforms (including both ambient and cultural noise) recorded by ~ 2600 seismic stations at epicentral distances up to 300 km. Earthquake waveforms are associated with about 450 K earthquakes with a diverse geographical distribution around the world. The majority of these earthquakes are smaller than M 2.5 and have been recorded within 100 km from the epicenter. A full description of properties of the dataset can be found in STEAD. Waveforms are 1 minute long with a sampling rate of 100 Hz and are causally band-passed filtered from 1.0-45.0 Hz.
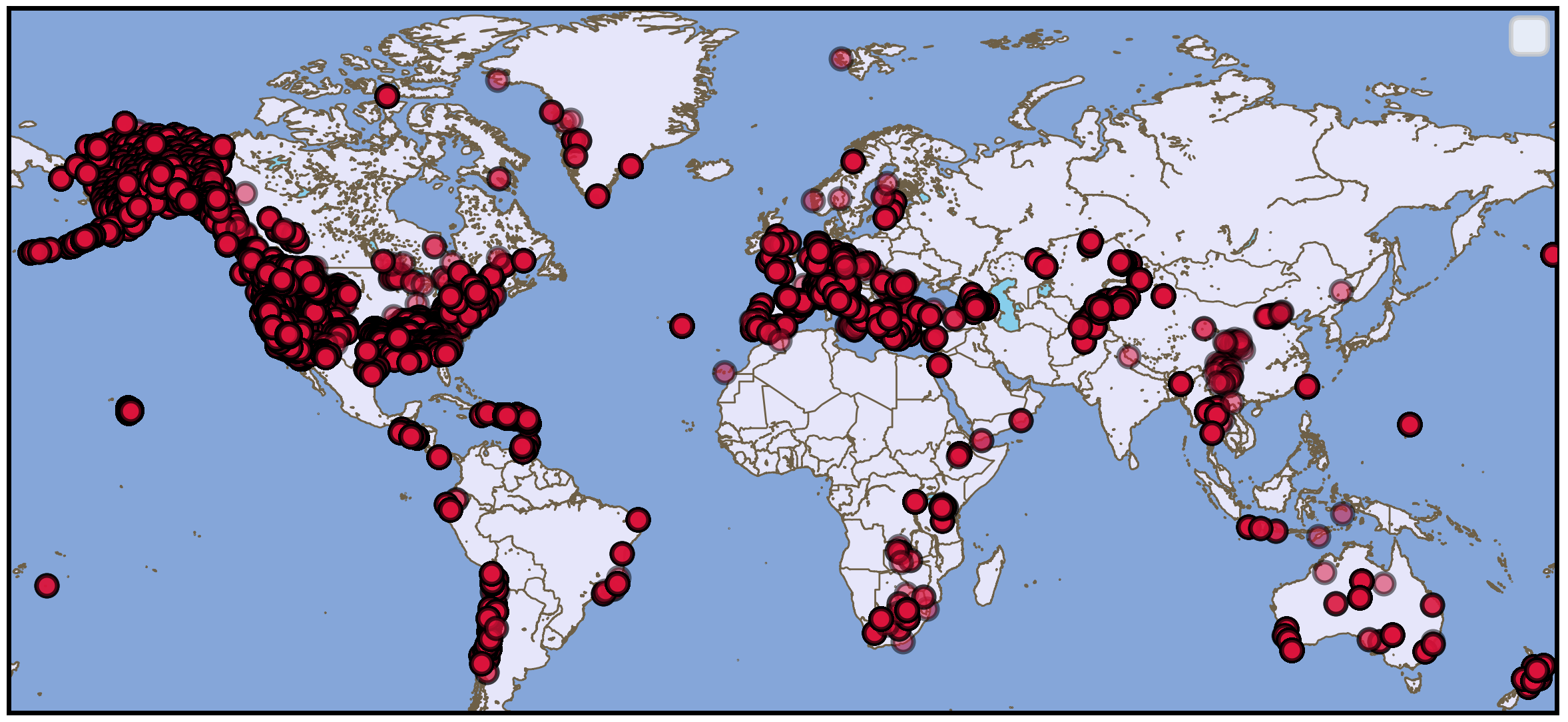
STEAD contains earthquake signals from most of the seismically active countries with a few exceptions like Japan.
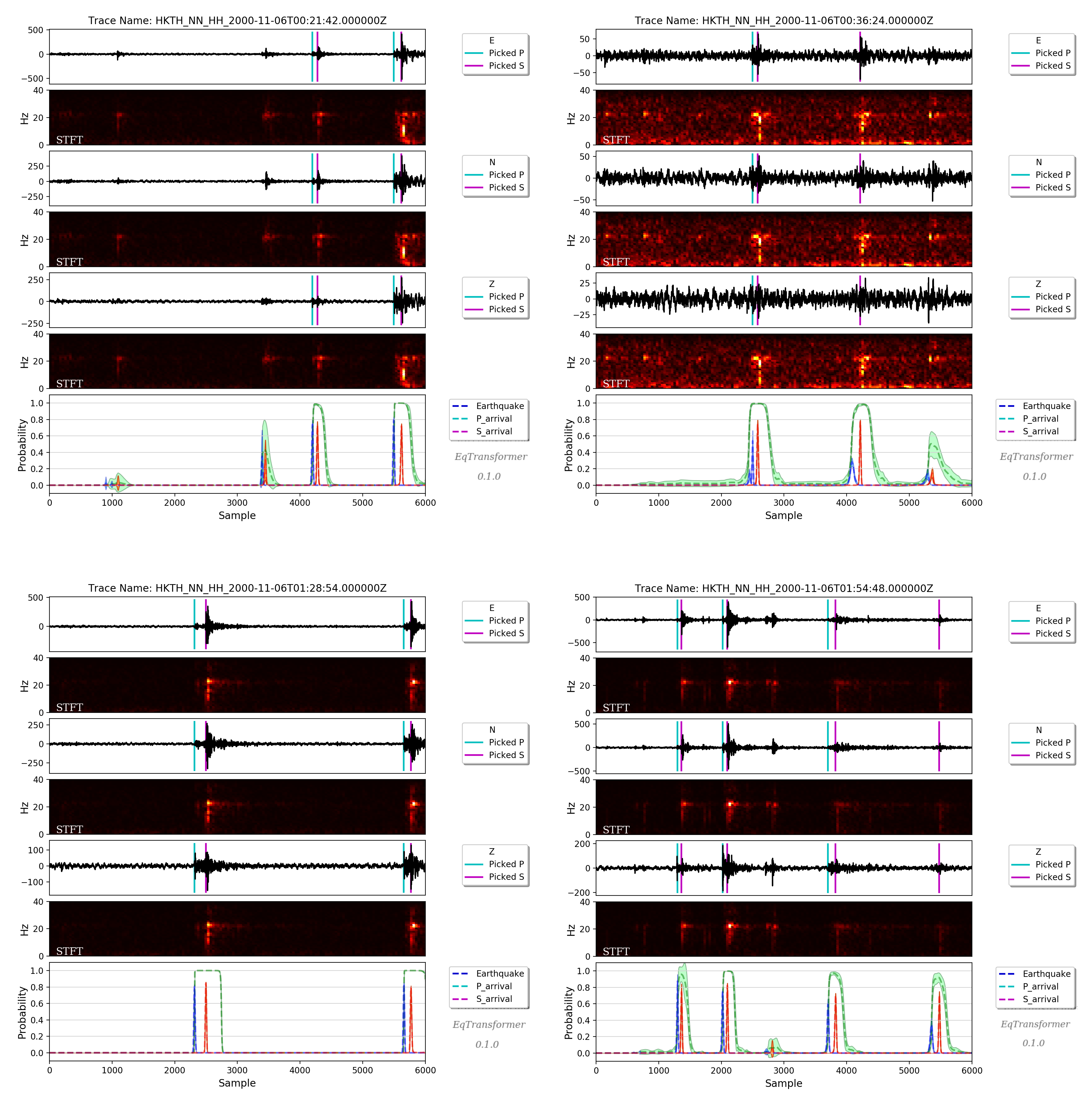
1.2. Application to Japan¶
However, EQTransformer has a high generalization ability. Applying it to 5 weeks of continuous data recorded during the 2000 Mw 6.6 western Tottori, Japan earthquake, two times more events were detected compared with the catalog of Japan Meteorological Agency (JMA).
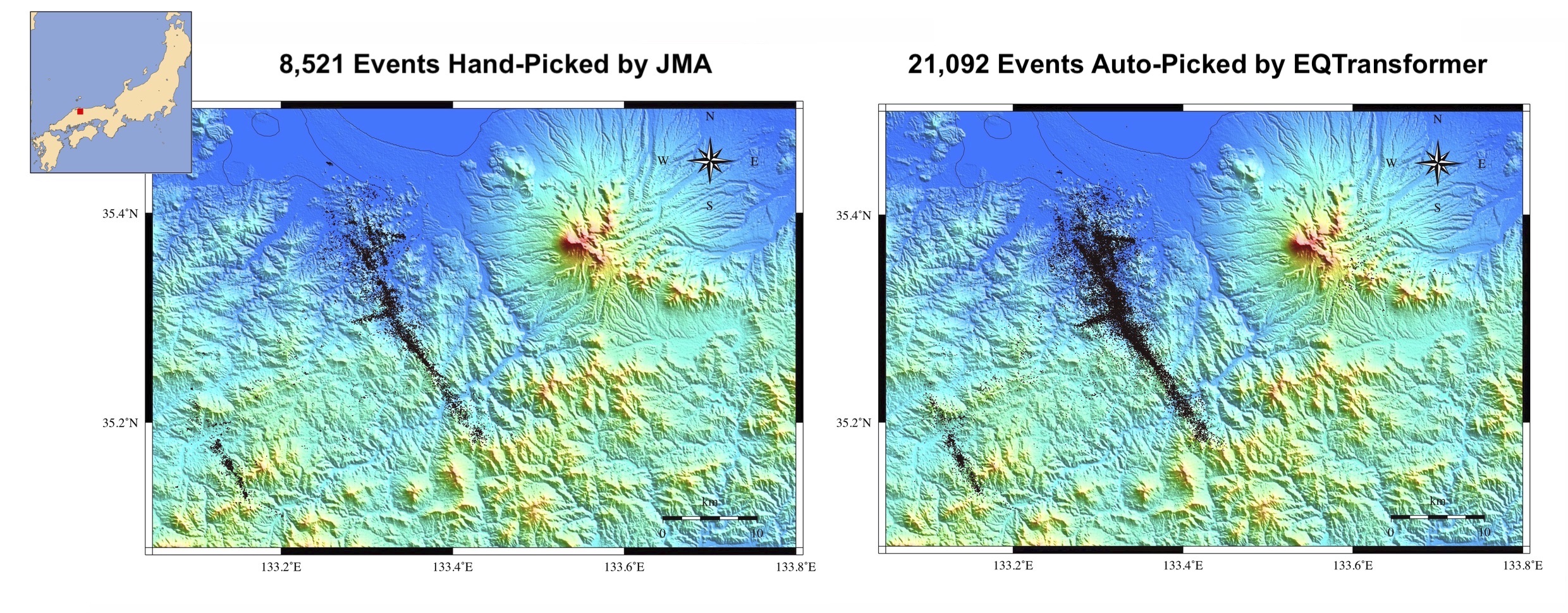
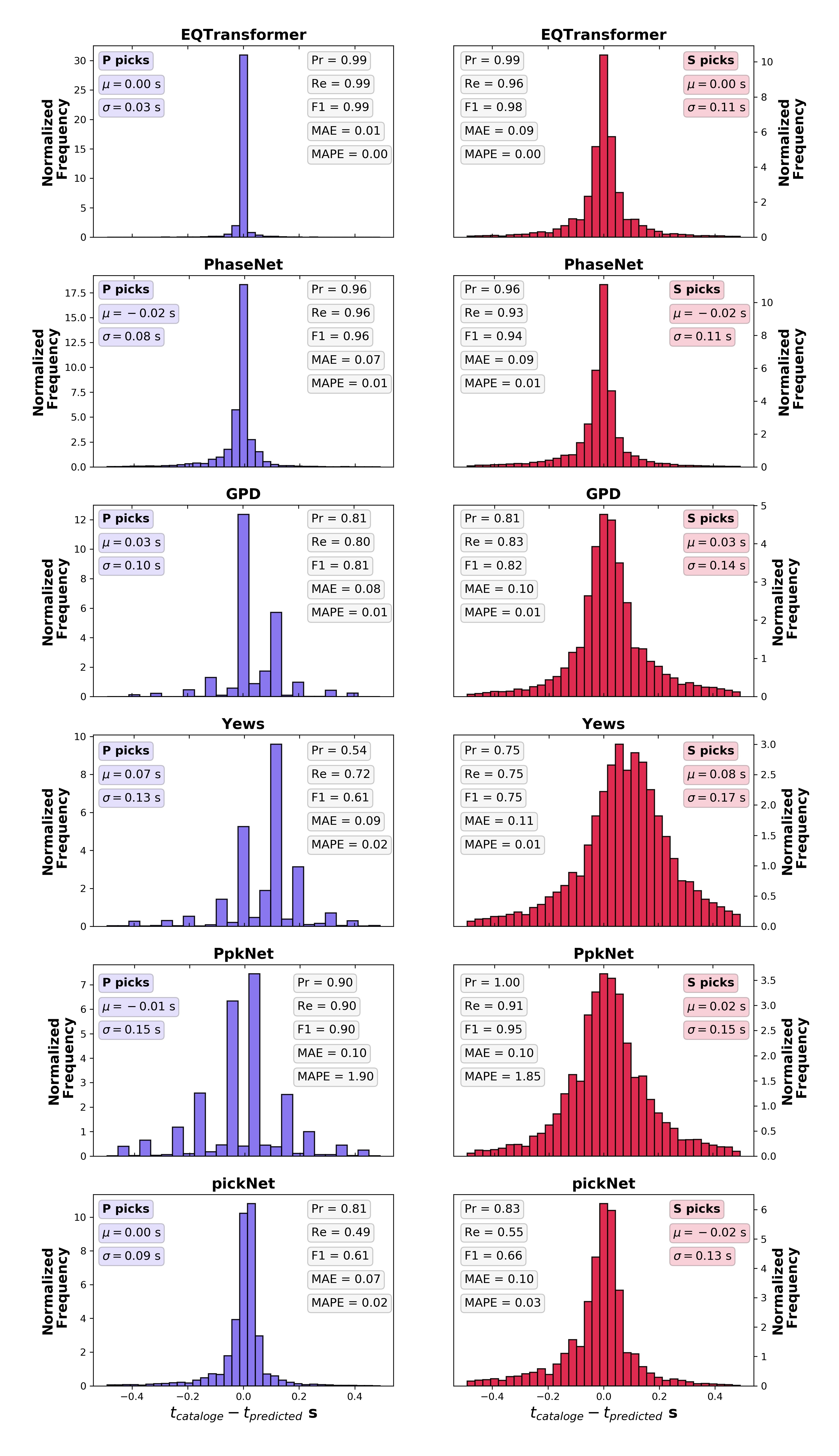
In total, JMA’s analysts picked 279,104 P and S arrival times on 57 stations, while EQTransformer was able to pick 401,566 P and S arrival-time on 18 of those stations (due to unavailability of data for other stations). To compare the manual picks by JMA with our automatic picks we used about 42,000 picks on the common stations and calculated the arrival time differences. The distributions of these arrival time differences between the manual and deep-learning picks for P and S waves are shown in the following figure. The standard deviation of differences between picks is around 0.08 second with a mean absolute error of around 0.06 second or 6 samples. The mean error is only 1 sample (0.01 s).
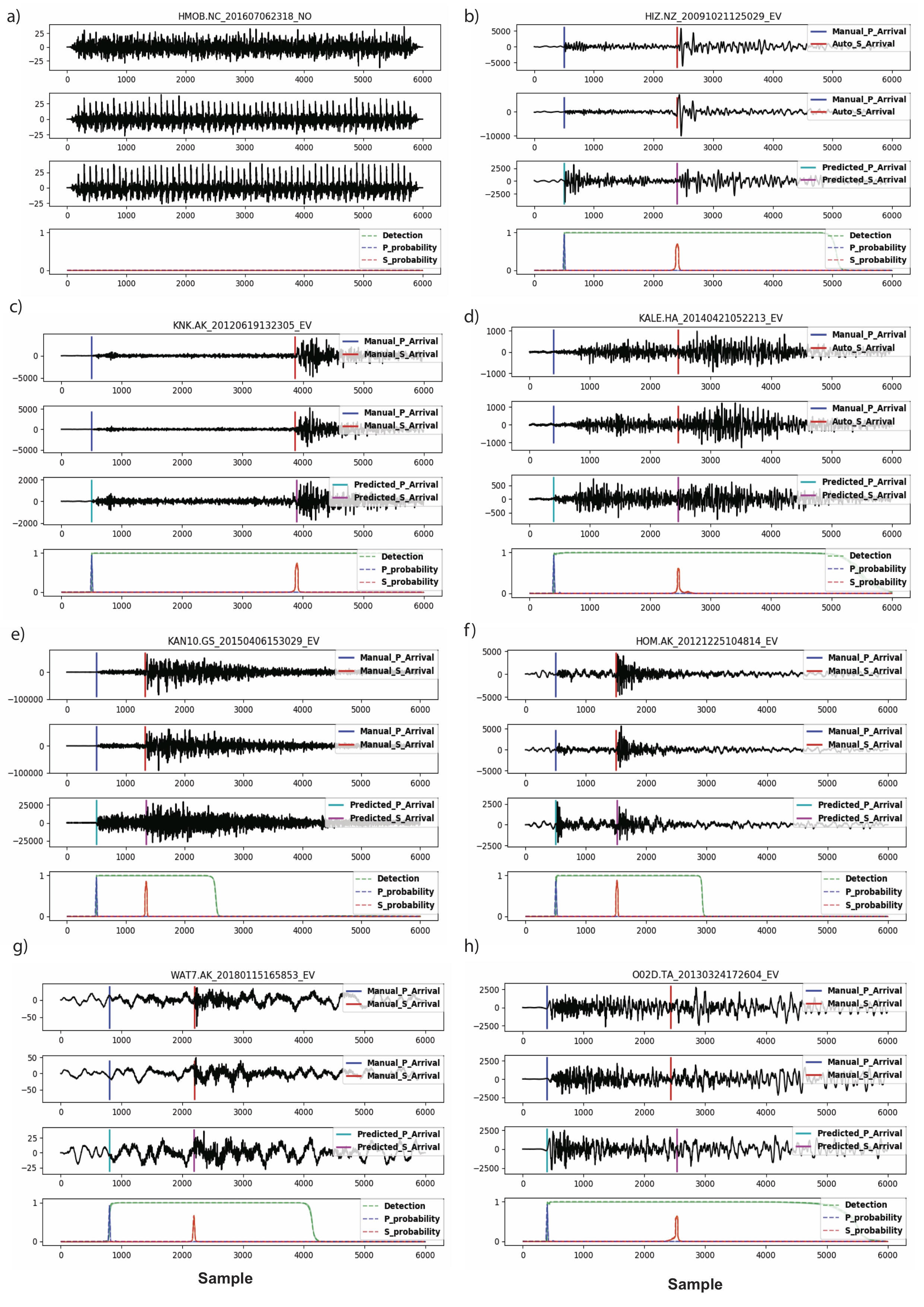
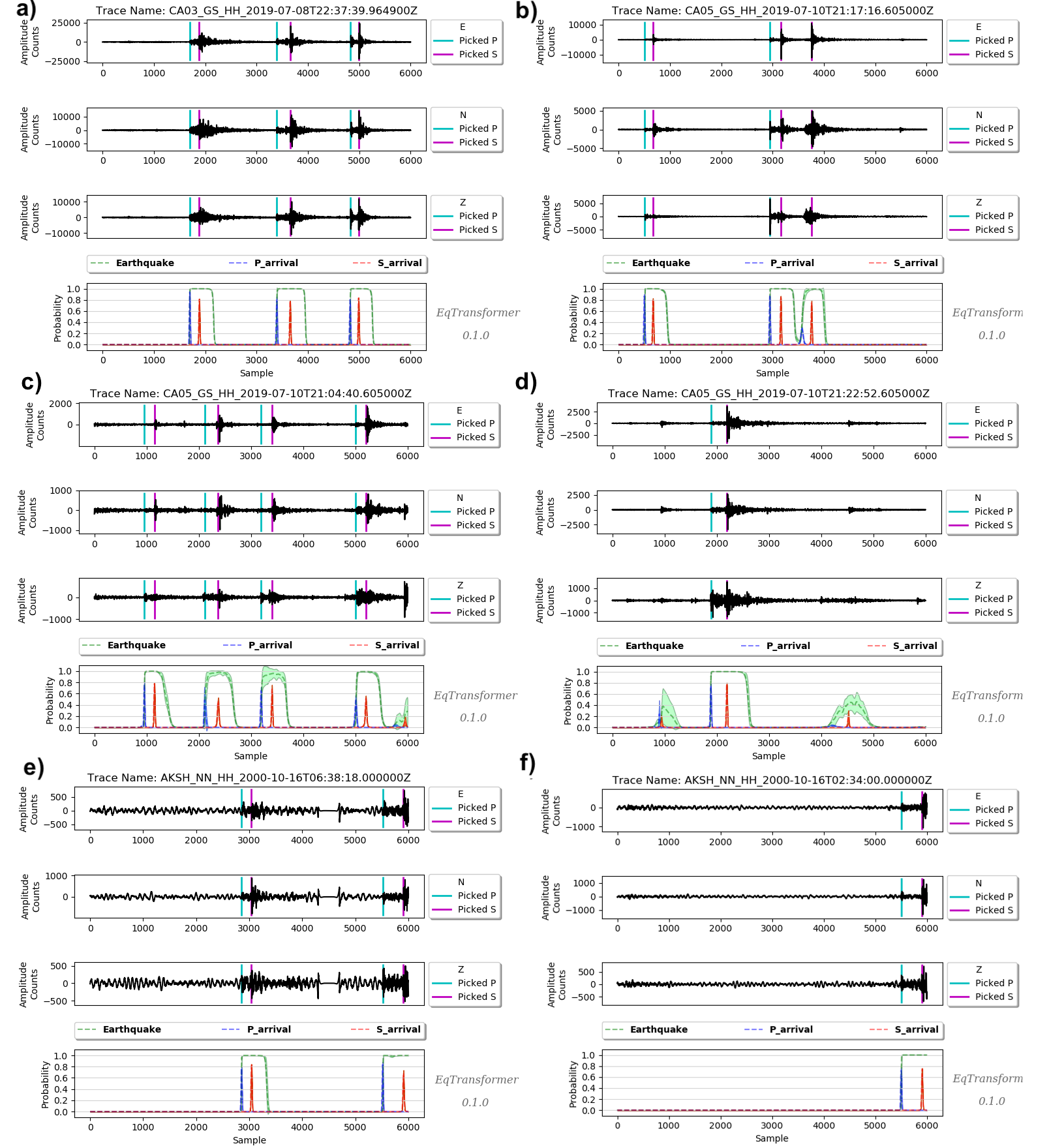
1.3. Application to Other Regions¶
Test set data from STEAD:
Ridgecrest, California:
Tottori, Japan:
West Texas, USA:
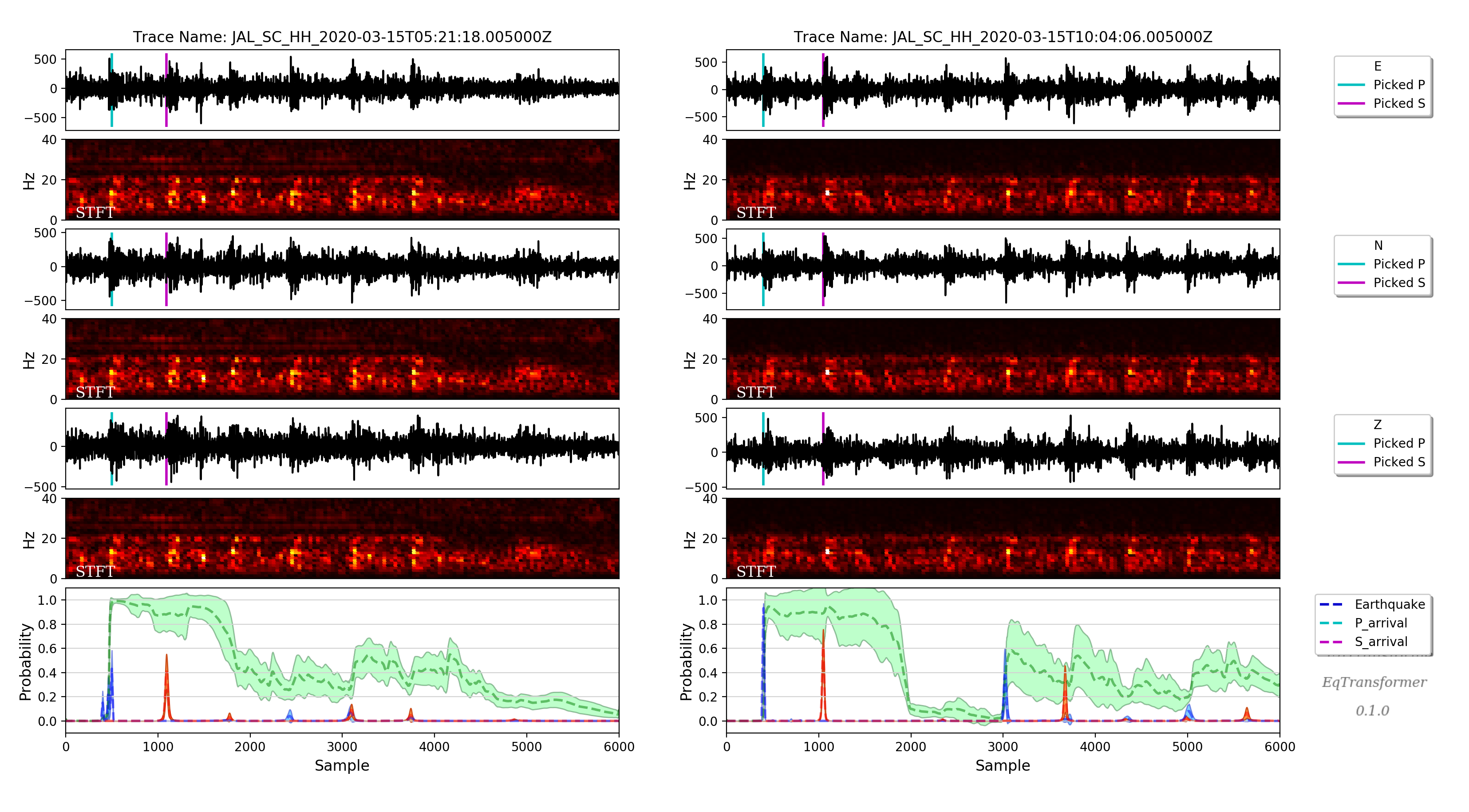
Variations in the output probability predictions (model uncertainty) can be useful to identify false-positive events (like the one shown in the above figure).